

Anatoly Zelenin
Schema Management in Kafka
6.05.2024In diesem Post erfährst du, wie explizite Schemas, dir dabei helfen, ein mögliches Chaos in Kafka zu vermeiden und wie die Schema Registries dabei unterstützen.
In diesem Post erfährst du, wie explizite Schemas, dir dabei helfen, ein mögliches Chaos in Kafka zu vermeiden und wie die Schema Registries dabei unterstützen.

In diesem Post zeige ich dir, wie du mithilfe von Debezium Daten aus verschiedenen Datenbanken zuverlässig und nahezu in Echtzeit nach Kafka importieren kannst. Debezium ist ein Kafka Connect-Plugin, das sich an das interne Log jeder Datenbank anschließen kann, um Änderungen zu erfassen und in Kafka zu schreiben.
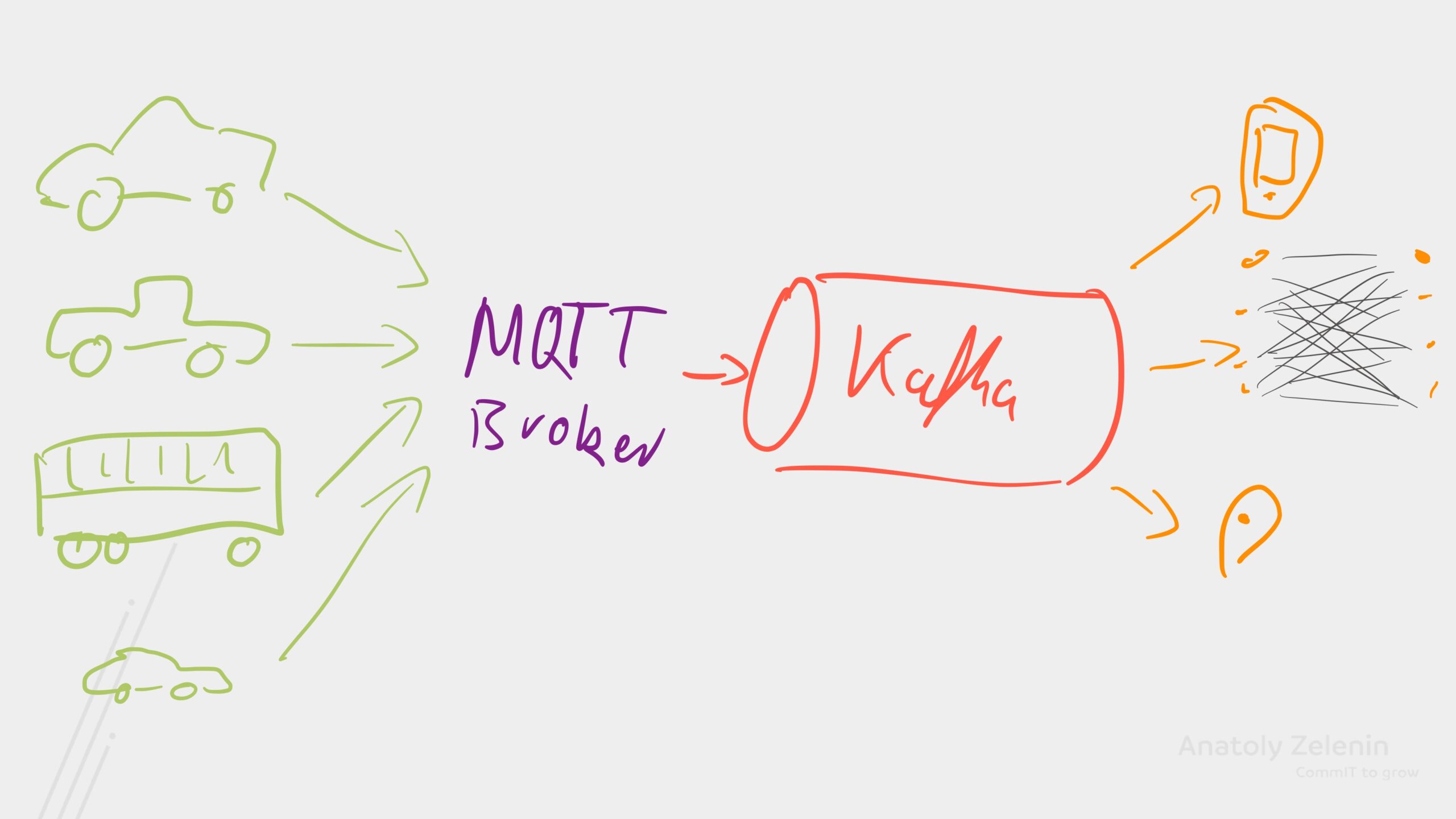
Moderne Fahrzeuge produzieren Unmengen an Daten. Damit fordern sie nicht nur Mobilfunknetze, sondern auch die IT-Systeme der Hersteller heraus. Wie kann Apache Kafka dabei helfen?
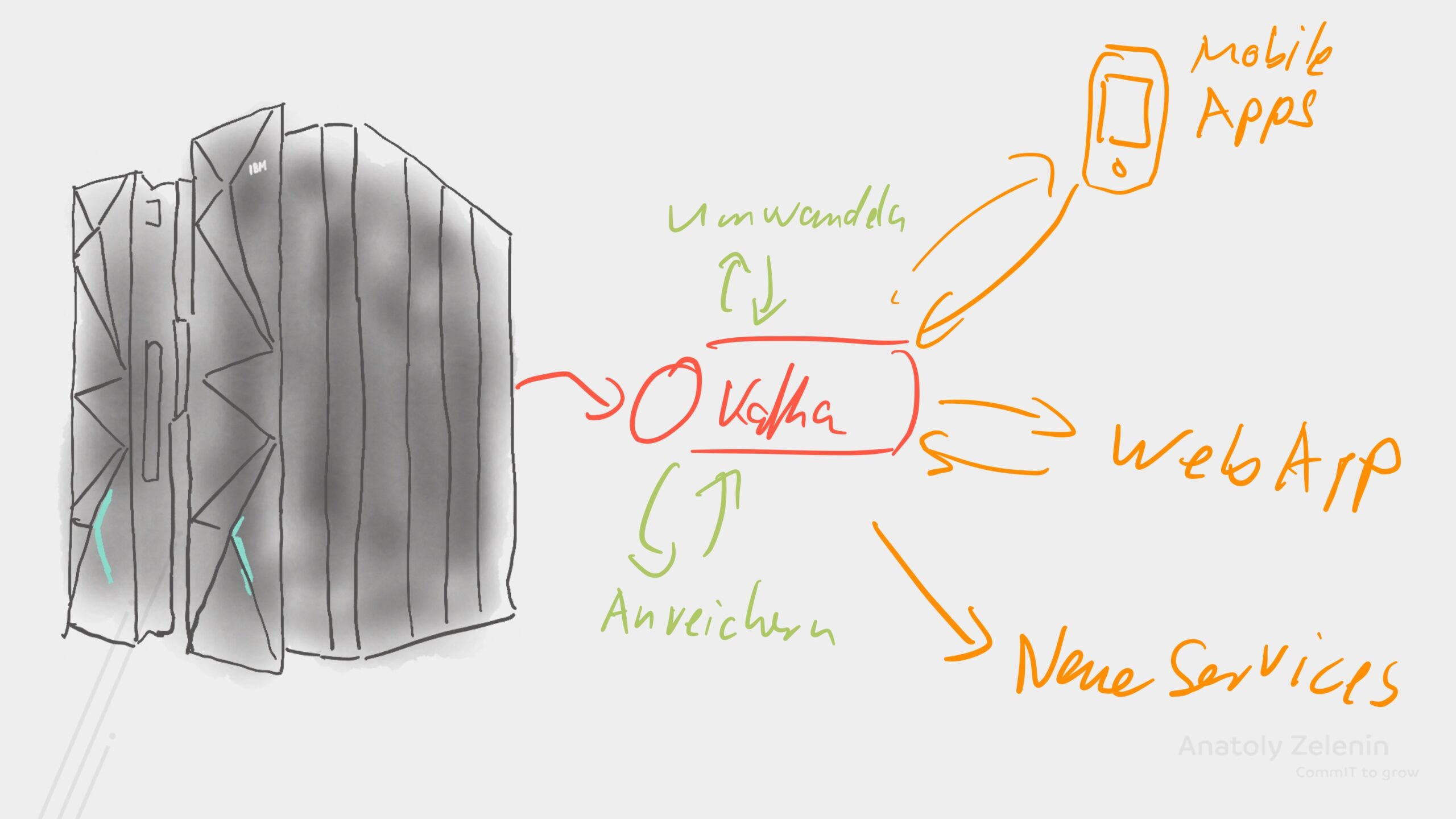
Kernbankensysteme kümmern sich um die wichtigsten Prozesse im Bankenwesen. Das Problem: Diese unbeweglichen Kolosse harmonieren nur selten mit den Wünschen der heutigen Kundinnen und Kunden. Es braucht Systeme, die das Alte mit dem Neuen verbinden. In vielen Bankhäusern wird dafür auf Apache Kafka gesetzt. Warum?
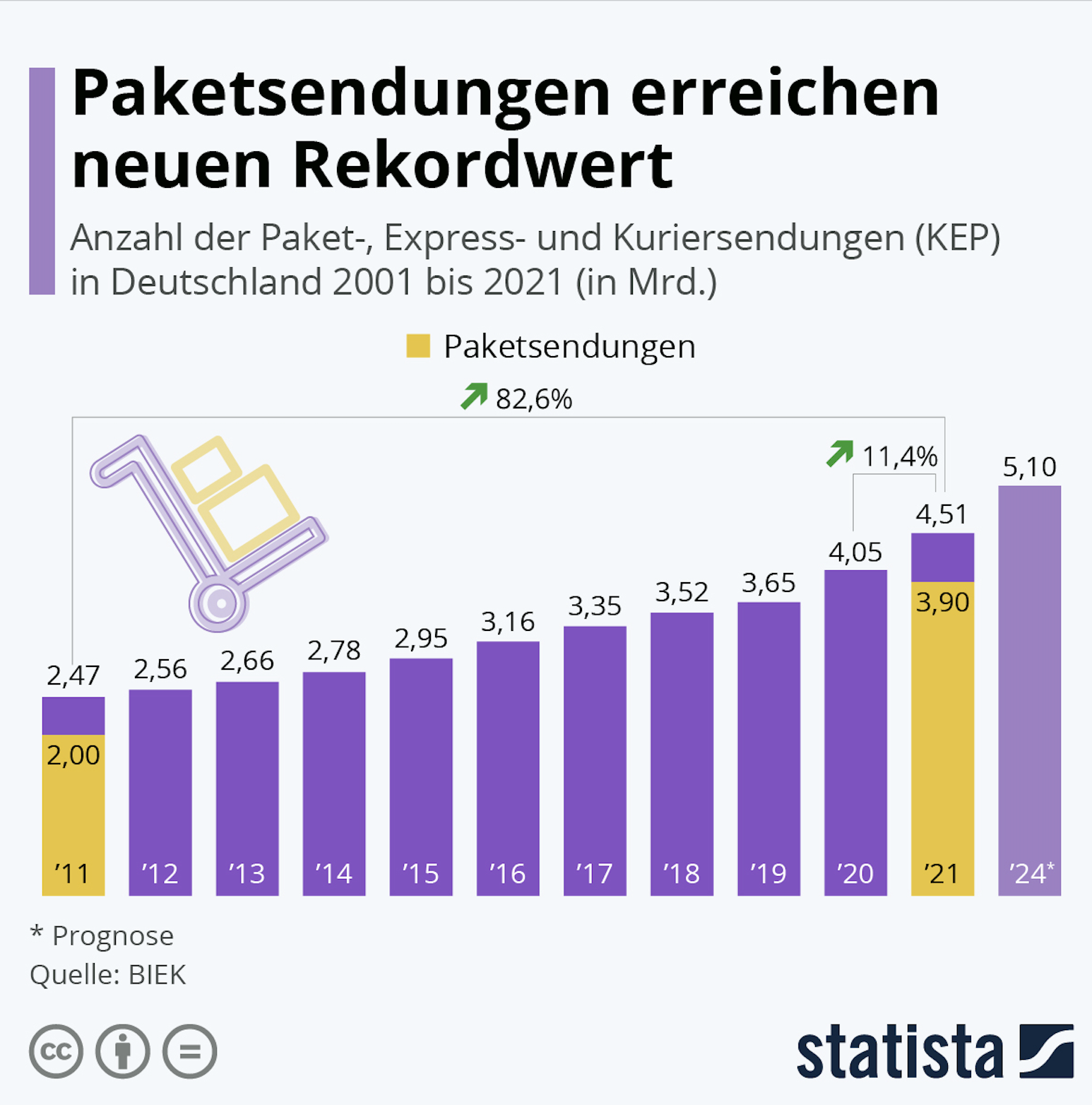
Wachsende Paketmengen. Poröse Lieferketten. Logistikfirmen stehen vor großen Problemen. Sie müssen mehr denn je in Echtzeit die richtigen Entscheidungen treffen. Das gelingt jedoch nicht ohne Echtzeitdaten. Wie Apache Kafka und dessen Ökosystem Unternehmen dabei helfen.

Wann bin ich ein guter Trainer? Das ist für mich vielleicht die wichtigste Frage in meiner Rolle als Apache-Kafka-Experte. In diesem Blog will ich sie mit sechs Leitprinzipien beantworten. Stimmst du mir bei allen zu?
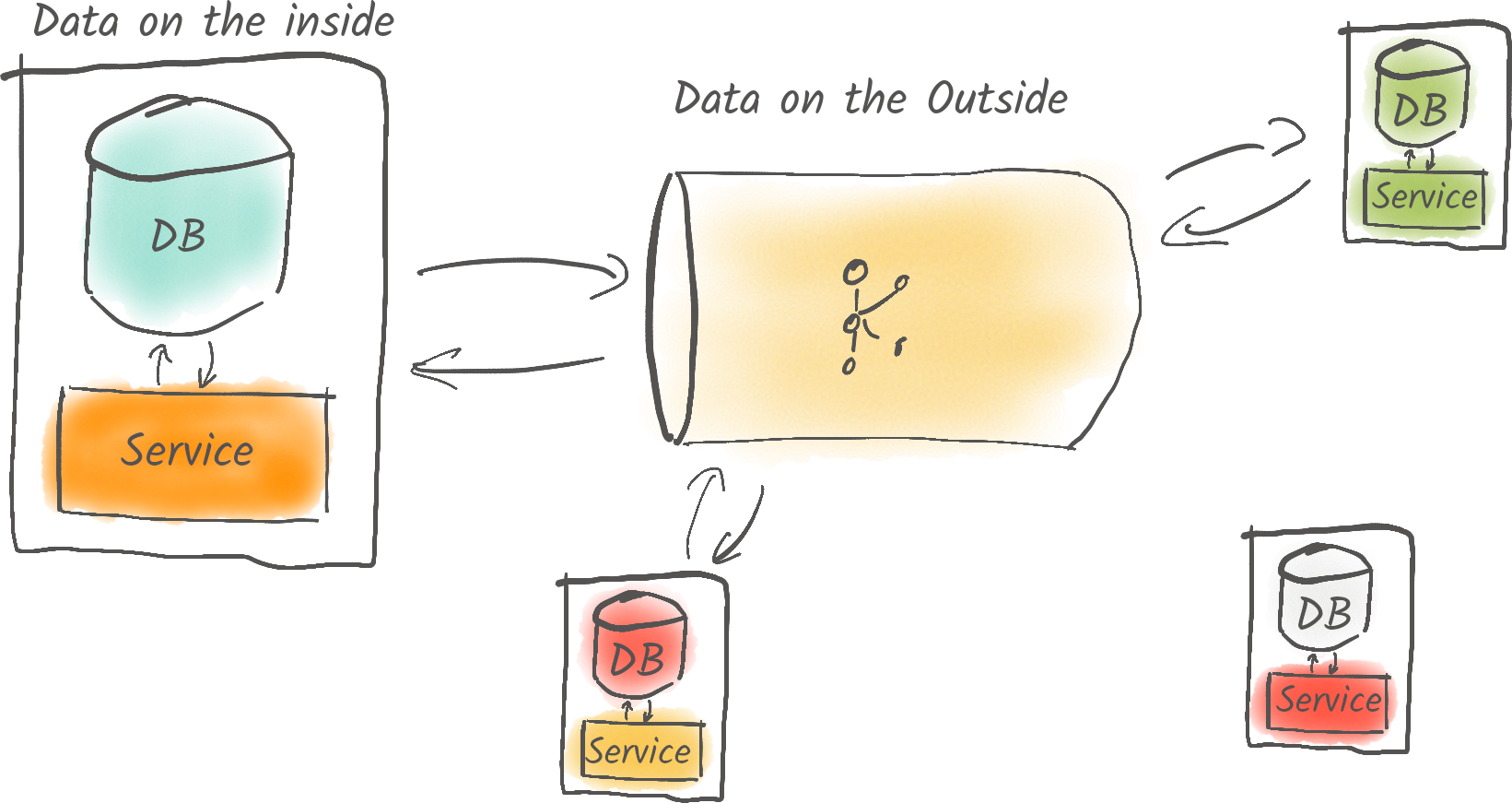
Daten liegen in Echtzeit vor. Die Infrastruktur für Microservices steht. Das Ziel ist klar: Wir wollen nun das Data Mesh. Doch wie erreichen wir damit unsere Fachbereiche? Warum das Datenmanagement eine Kultur- und Produktfrage ist.

Das „Data Mesh“ ist in der IT-Szene ein echter Hype. Warum Unternehmen von einer dezentralisierten Datenarchitektur profitieren und wie Apache Kafka beim Etablieren dieser neuen Struktur hilft, erörtert dieser Artikel.
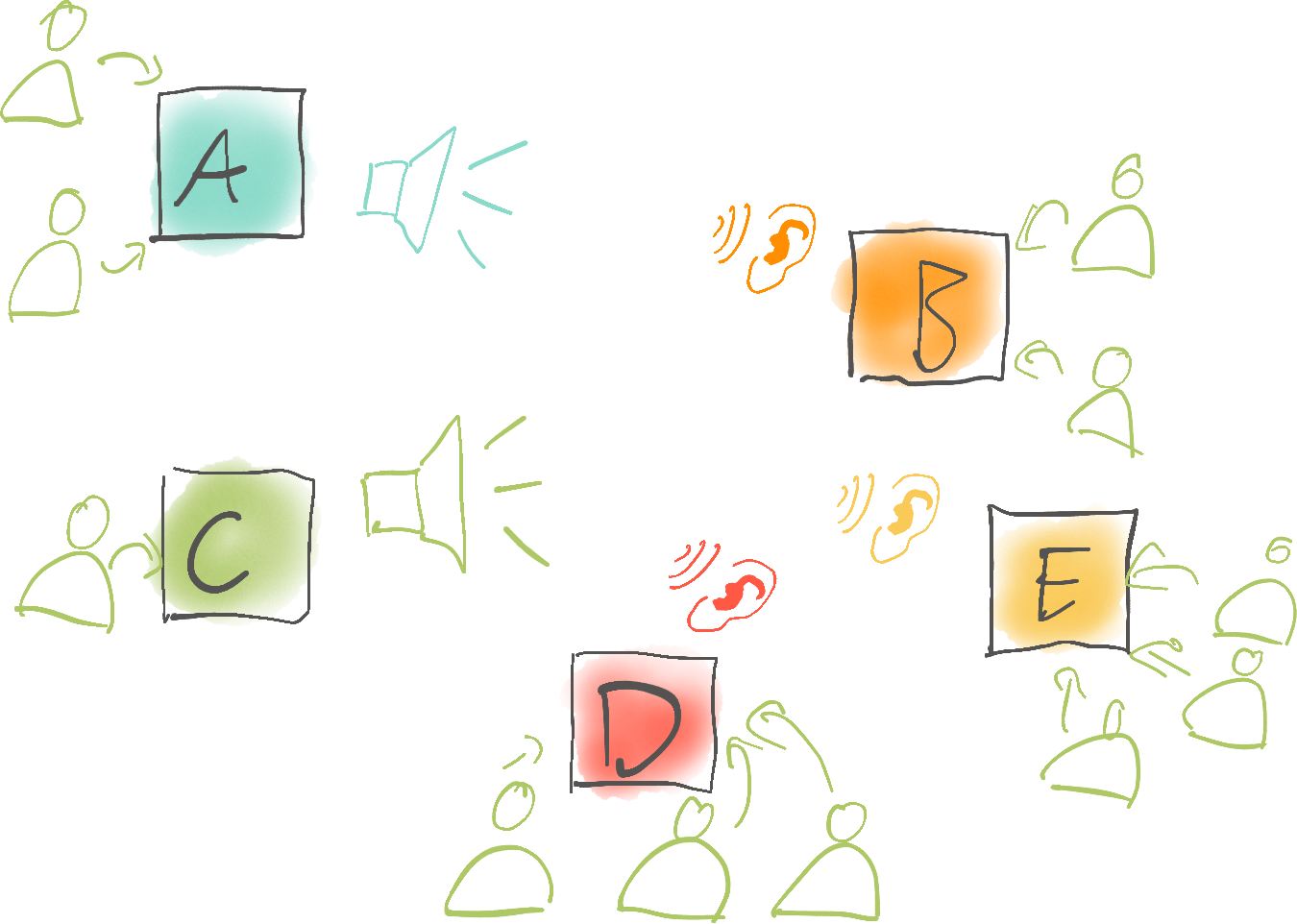
Von Start-up bis Konzern – immer mehr Unternehmen setzen auf Microservice-Architekturen. In der zweiten Lektion der vierteiligen Blogreihe erfährst du, wie Unternehmen mithilfe von Apache Kafka die Kommunikation zwischen ihren Services vereinfachen.

Jedes Unternehmen, das unzählige Datenströme verarbeitet, kann diese mithilfe von Apache Kafka optimieren. Die erste Lektion dieser vierteiligen Blog-Reihe zeigt dir, warum sich größere Organisationen dieser Software zuwenden sollten.