Debezium: Change Data Capture für Apache Kafka
14.02.2024
Anatoly Zelenin
IT-Trainer und Apache Kafka Experte
In meiner Apache Kafka Mittagsakademie können Teilnehmerinnen und Teilnehmer meiner Kafka Kurse weitere interessante Themen kennenlernen, auch wenn die Schulung eigentlich schon vorbei ist. Dieser Blogpost ist ein bearbeitetes Transkript des Videos. Die praktischen Übungen stehen exklusiv den Teilnehmenden zur Verfügung. Wenn du dich auch darin ausprobieren möchtest, dann schreib mir gerne.
In der heutigen datengetriebenen Welt ist die Fähigkeit, Daten nahtlos zwischen verschiedenen Systemen zu bewegen, von unschätzbarem Wert. Eines der Schlüsselelemente in modernen Datenarchitekturen ist Apache Kafka, ein leistungsstarkes Tool für die Verarbeitung von Streaming-Daten. Doch wie integriert man Daten aus einer Vielzahl von Datenbanken zuverlässig und in nahezu Echtzeit in Kafka? Hier kommt Debezium ins Spiel, ein Open-Source-Datenstreaming-Tool, das genau dieses Problem löst.
Debezium ermöglicht es uns, Änderungen in unseren Datenbanken zu erfassen und diese Änderungen als Event-Stream nach Kafka zu leiten. Dieser Prozess, bekannt als Change Data Capture (CDC), ist entscheidend für die Erstellung reaktiver Anwendungen, die in Echtzeit auf Datenänderungen reagieren müssen.
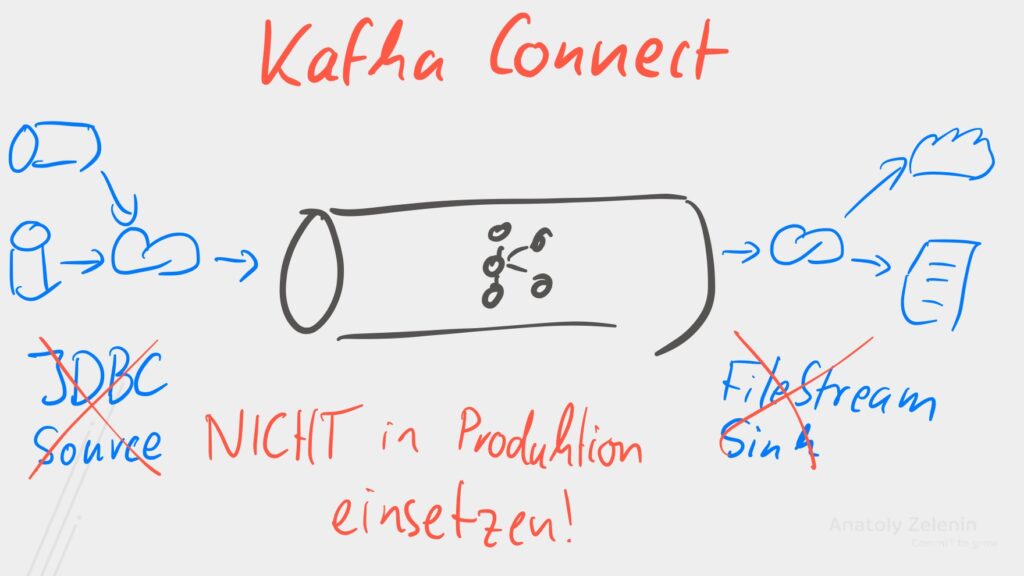
Während es eine Vielfalt von Werkzeugen gibt um Daten nach Kafka zu befördern, möchte ich eine
besondere Anmerkung zum JDBC Source Connector machen. In meinen Schulungen weise ich stets darauf hin, dass wir mit
diesem speziellen Connector vorsichtig sein sollten. Der Grund dafür liegt unter anderem in seiner simplen Abfrage-Methodik, wie zum
Beispiel SELECT * FROM TABLE WHERE id/timestamp > ?, die uns vor Herausforderungen stellt, wenn es darum geht, UPDATEs
effektiv zu erfassen und DELETEs zu bemerken.
Change Data Capture
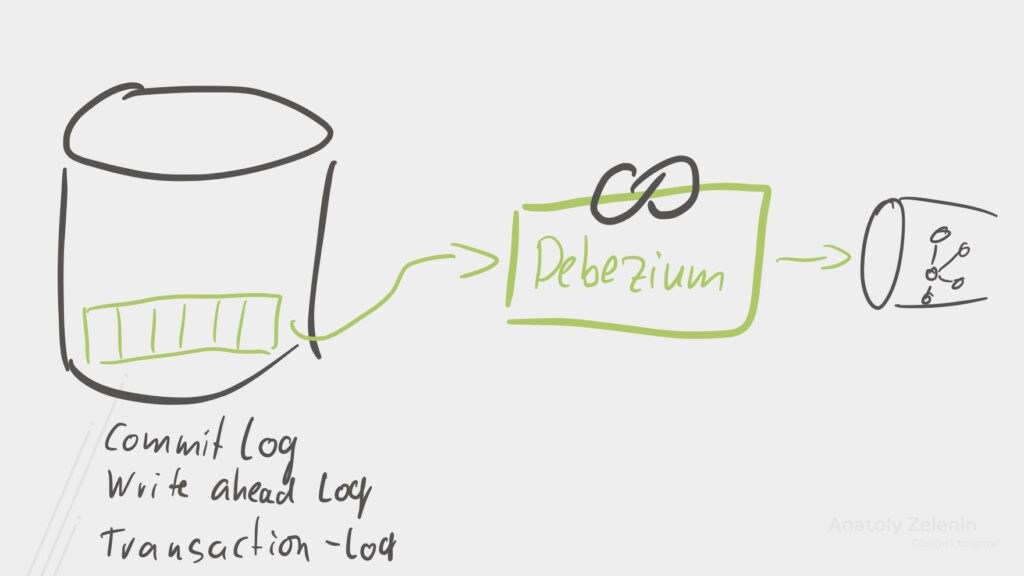
Außerdem freuen sich unsere Datenbank-Admins nicht unbedingt über diese Zusatzlast auf der Datenbank, aber es gibt eine bessere Lösung: Nahezu jede Datenbank hat intern ein Log, in das jede Änderung geschrieben wird. Manche Datenbanken nennen es das Transaktions-Log manche das Commit-Log oder manche Write Ahead Log.
Datenbanken nutzen dieses Log, um für höhere Zuverlässigkeit zu sorgen
oder auch um Daten zwischen Replicas zu replizieren. Mithilfe von
Debezium können wir uns an dieses Log anschließen und Daten aus der
Datenbank dann schreiben, wenn sie sich verändern, also bei einem
INSERT einem UPDATE unter gar einem DELETE.
Dabei ist Debezium lediglich ein Kafka Connect Plugin und unterstützt zahlreiche Datenbanksysteme wie PostgreSQL, MySQL, Oracle, Microsoft SQL Server oder gar MongoDB. Da Debezium nur aus dem Transaktions-Log liest (zumindest bei den meisten Datenbanken) und keine Queries abfeuert, ist der Overhead Debeziums meistens vernachlässigbar.
PostgreSQL konfigurieren

Der Nachteil ist aber, dass ein paar Vorbereitungen zu tun sind. Lass
uns das gemeinsam anhand des Beispiels PostgreSQL anschauen. Im Lab ist
das schon vorbereitet. Als Erstes müssen wir das
Log Level für den Write
Ahead Log (wal_level) erhöhen. Der Default ist
replica, welches ausreicht, um Daten auf Read-Only Replicas zu
replizieren. Aber wir benötigen für Debezium ein paar mehr Daten und
erhöhen das Level auf logical. Danach müssen wir aber Postgres neu
starten.
Das
wal_levelzu erhöhen geht auch bei AWS und Co prüfe dazu am besten die Debezium Doku.
Als Nächstes müssen wir unserem Datenbanknutzer die Rechte geben, Daten
zu replizieren. Dafür fügen wir dem Nutzer einfach die Rolle
REPLICATION hinzu.
Natürlich umschifft Debezium dabei nicht alle Sicherheitsmechanismen und
gibt Zugriff auf alle Daten in allen Tabellen, sondern es erstellt eine
sogenannte Publication, in die die Daten für die benötigten Tabellen
gesammelt sind. Das wird aber automatisch von Debezium erledigt, und wir
müssen es nicht manuell tun.
Connector konfigurieren
Als Nächstes konfigurieren wir uns den Connector. Wir müssen die
Datenbank Zugangsdaten setzen und definieren, welche Tabellen verbunden
beziehungsweise nicht verbunden werden sollen. Zu guter Letzt setzen wir
das Topic Präfix, denn Debezium erstellt uns Topics nach dem Muster
prefix.schema.table. Das können wir aber auch ändern. Hier ist ein Beispiel für eine einfache Konfiguration:
{
"name": "debezium",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "user",
"database.password": "password",
"database.dbname" : "user",
"plugin.name": "pgoutput",
"publication.autocreate.mode": "filtered",
"topic.prefix": "dbz",
"schema.include.list": "public"
}
}Dieser Connector schreibt alle Daten aus allen Tabellen des public-Schemas der user-Datenbank auf localhost nach Kafka. Dabei werden die Kafka-Topics nach dem folgenden Muster benannt: dbz.public.[table-name].
Nachdem wir also den Connector erstellt haben, fängt Debezium an, die Daten zu replizieren. Das Problem ist aber, dass im Write Ahead Log nicht die Daten für alle Ewigkeit aufbewahrt werden. Deshalb macht Debezium beim ersten Start einen initialen Snapshot aller Daten in allen angefragten Tabellen. Und erst danach fängt der Change Data Capture-Teil an. Debezium garantiert uns sogar, dass dies konsistent passiert.
Debeziums Nachrichtenformat
{
"schema": {
…
},
"payload": {
"before": null,
"after": {
"id": 1004,
"first_name": "Foo",
"last_name": "Bar",
"email": "foo@example.com"
},
"source": {
"version": "2.3.0.Final",
"name": "dbserver1",
"server_id": 0,
"ts_sec": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"snapshot": true,
"thread": null,
"db": "inventory",
"table": "customers"
},
"op": "r",
"ts_ms": 1486500577691
}
}Wie sehen aber die Daten aus, die Debezium schreibt? Denn Debezium
schreibt nicht nur die Veränderung, sondern ein paar mehr Informationen.
Das Schema (schema) der Daten wird auch in jeder Nachricht
gespeichert.
Wir können Schema Registry benutzen, um diese Daten nicht jedes Mal
mitzuschicken. Dazu aber etwas mehr in einem späteren Modul. Der
eigentliche Payload (payload) besteht aus einigen Metadaten zur
Datenquelle, dem source Block, der Operation(op), die diese
Nachricht ausgelöst hat. Also war das ein Create (c), Update
(u), Delete (d) oder ein Read (r)? Reads passieren aber nur
beim Snapshot und natürlich den Timestamp (ts_ms). Mehr Infos
findest du im
Debezium Tutorial.
Die wichtigsten Felder sind aber before, also der Zustand des
Eintrags vor der Operation und after, der Zustand des Eintrags nach
der Operation. Aber oft interessieren uns die meisten Daten hier gar
nicht, dafür können wir auch das
Event Flattening SMT
benutzen, um die ganzen Zusatzdaten nicht
mitzuschreiben. Dann wird Debezium lediglich den after Payload nach
Kafka schreiben.
Anatoly Zelenin vermittelt als IT-Trainer hunderten Teilnehmern Apache Kafka in interaktiven Schulungen. Seine Kunden aus dem DAX-Umfeld und dem deutschen Mittelstand schätzen seit über einem Jahrzehnt seine Expertise und seine begeisternde Art. Darüber hinaus ist er nicht nur IT-Berater und -Trainer, sondern erkundet auch als Abenteurer unseren Planeten.