Apache Kafka Testumgebung aufsetzen
17.11.2021
Anatoly Zelenin
IT-Trainer und Apache Kafka Experte

Alexander Kropp
Dozent und Trainer im Cloud-Umfeld
Es gibt unterschiedliche Arten, eine Testumgebung für Apache Kafka aufzusetzen. Die Umgebung aus diesem Artikel reicht vollkommen aus, um erste Schritte mit Kafka zu gehen oder für eine lokale Entwicklungsumgebung. Für Produktion ist sie aber in keinster Weise geeignet!
In diesem Artikel möchten wir zwei Varianten durchgehen:
- Per Kommandozeile: Dafür benötigen wir keine zusätzlichen Werkzeuge, sondern setzen sie mit der Open Source-Distribution von Kafka in wenigen Minuten auf.
- Per GUI mit KaDeck: KaDeck ist ein super Werkzeug, um per GUI auf Kafka zuzugreifen. Es bringt auch eine einfache Möglichkeit mit, einfache Kafka Cluster per Mausklick zu starten.
Gemeinsamkeiten beider Ansätze
Mit beiden Ansätzen setzen wir ein einfaches Kafka Cluster bestehend aus einem Zookeeper-Knoten und einem einzelnen Kafka Broker auf. Damit haben wir ein lokales Cluster und können lokale Software dagegen testen und unsere ersten Schritte mit Kafka wagen. Wenn es mehr sein sollte, können wir relativ einfach weitere Broker (und Zookeeper-Knoten) starten.

Apache Kafka herunterladen

Die aktuelle Kafka-Version finden wir unter Kafka Downloads. Zum Zeitpunkt des Schreibens ist die Version 3.1 aktuell.
Wir empfehlen den binären Download in der aktuellen Scala-Version, welche zum Zeitpunkt des Schreibens kafka_2.13-3.1.0.tgz ist. Am einfachsten ist es, wenn wir die entsprechende Version herunterladen, entpacken und an den gewünschten Ort verschieben. Zum Beispiel nach ~/kafka (also unser Nutzer-Verzeichnis).
Alternativ können wir den Download auch über die Kommandozeile vornehmen:
$ export KAFKA_VERSION=3.1.0
$ wget "https://downloads.apache.org/kafka/${KAFKA_VERSION}/kafka_2.13-${KAFKA_VERSION}.tgz"
$ tar xfz kafka_2.13-${KAFKA_VERSION}.tgz
$ rm kafka_2.13-${KAFKA_VERSION}.tgz
$ cp -a kafka_2.13-${KAFKA_VERSION}/. ~/kafka
$ rm -r kafka_2.13-${KAFKA_VERSION}Im Ordner ~/kafka finden wir folgende Ordner und Dateien:
LICENSE,NOTICE: Dateien mit Lizenzinformationenbin: Kommandozeilenwerkzeuge zur Interaktion mit Kafka und Zookeeperconfig: Konfigurationsdateienlibs: Java-Bibliotheksdateien (*.jar)site-docs: Dokumentation
Damit wir beim Ausführen der Kommandozeilenwerkzeuge nicht immer den gesamten Pfad angeben müssen, fügen wir den bin-Ordner zur PATH-Variable hinzu:
$ export PATH=~/kafka/bin:"$PATH"Natürlich können wir diese Zeile auch in unsere ~/.bashrc, ~/.zshrc oder Ähnlichem hinzufügen, je nachdem, welche Shell wir benutzen.
Kafka per Kommandozeile starten
Um Kafka zu starten, müssen wir zuerst Zookeeper starten:
$ zookeeper-server-start.sh ~/kafka/config/zookeeper.propertiesNach einigen Sekunden sollten wir folgende Zeilen in der Ausgabe wiederfinden:
[…] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[…]
[…] INFO Creating new log file: log.25 (org.apache.zookeeper.server.persistence.FileTxnLog)Damit läuft Zookeeper und wir können als nächstes Kafka starten. Dafür öffnen wir ein neues Terminal-Fenster und führen folgenden Befehl aus:
$ kafka-server-start.sh ~/kafka/config/server.propertiesZwischen den vielen [INFO]-Meldungen sollten wir folgende Zeile erspähen:
[…] INFO [TransactionCoordinator id=0] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator)Damit ist auch Kafka gestartet. Da es sehr umständlich ist, jedes Mal zwei Terminal-Fenster laufen zu haben, können wir sowohl Zookeeper als auch Kafka im Daemon-Mode im Hintergrund starten. Und zwar mit folgenden zwei Befehlen (vorher die bisherigen Kommandos abbrechen):
$ zookeeper-server-start.sh -daemon ~/kafka/config/zookeeper.properties
$ kafka-server-start.sh -daemon ~/kafka/config/server.propertiesZum Stoppen führen wir folgende Befehle aus:
$ kafka-server-stop.sh
$ zookeeper-server-stop.shUm uns unser Leben zu erleichtern, können wir die Befehle zum Starten und Stoppen in Scripte packen, wie zum Beispiel hier.
Nachdem wir Kafka gestartet haben, ist es Zeit für die ersten Schritte mit Kafka.
Per GUI mit KaDeck
KaDeck ist ein super Werkzeug um einen Einblick zu bekommen, was gerade in Kafka passiert. Wir haben mit KaDeck die Möglichkeit, Daten in Topics anzusehen, zu produzieren, aber auch Consumer Groups zu verwalten. Die vielen weiteren Funktionen und Features lassen wir hier außen vor.
Nachdem wir Kafka heruntergeladen haben, müssen wir noch KaDeck herunterladen. Dazu wählen wir auf der KaDeck-Seite die Desktop-Version aus und laden sie herunter.

Nach der Installation sehen wir folgendes Bild:

Wir klicken auf Setup und müssen dann im Feld Embedded Cluster lediglich den absoluten Pfad zu unserem Kafka-Ordner hinzufügen. Bei mir ist dies der Pfad /Users/az/kafka:

Nun sagen wir “Run”! Und warten, bis Kafka gestartet ist:

Nach einigen Sekunden zeigt uns KaDeck auf der rechten Seiten Informationen über unser gerade eben gestartetes Kafka Cluster an:
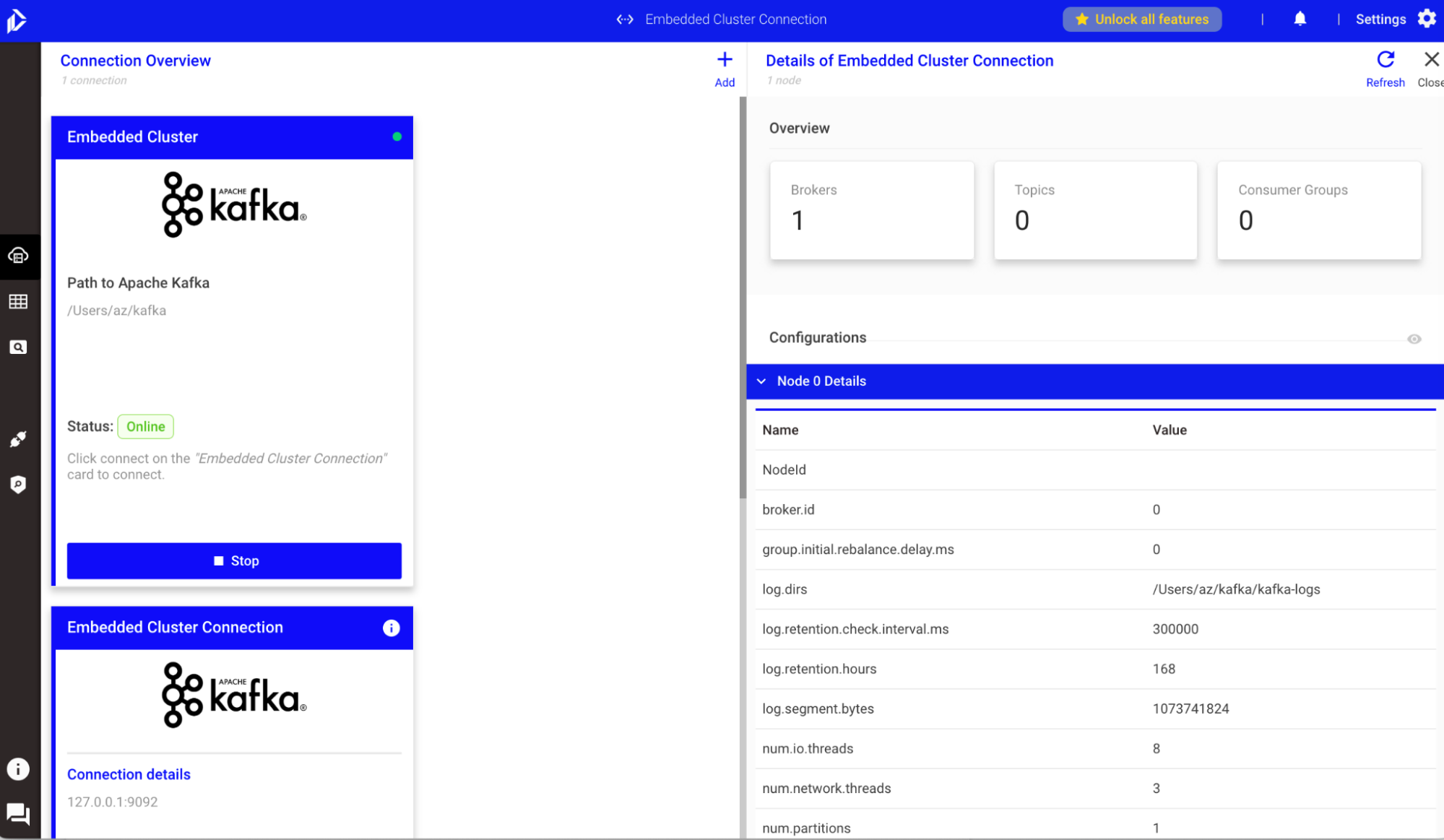
Zum Stoppen klicken wir auf Stop.
Nachdem wir Kafka gestartet haben, ist es Zeit für die ersten Schritte mit Kafka.
Du möchtest Kafka nicht nur in einer Testumgebung laufen lassen, sondern auch in Produktion? Ich unterstütze Dich und Dein Team gerne dabei. Schreib mir gerne eine Nachricht
Anatoly Zelenin vermittelt als IT-Trainer hunderten Teilnehmern Apache Kafka in interaktiven Schulungen. Seine Kunden aus dem DAX-Umfeld und dem deutschen Mittelstand schätzen seit über einem Jahrzehnt seine Expertise und seine begeisternde Art. Darüber hinaus ist er nicht nur IT-Berater und -Trainer, sondern erkundet auch als Abenteurer unseren Planeten.
Alexander Kropp ist seit seiner Kindheit leidenschaftlicher Informatiker und programmiert seit er 10 Jahre alt ist. Als Forscher und Berater unterstützt Alexander seit einem Jahrzehnt namhafte Unternehmen bei der Digitalisierung und Prototypen-Entwicklung. Parallel ist er als Dozent und Trainer im Cloud-Umfeld tätig.